转载自:
1、Golang内存对齐 - 简书 (jianshu.com)
如何得到一个对象所占内存大小?
fmt.Println(unsafe.Sizeof(int64(0))) // "8"
type SizeOfA struct {
A int
}
unsafe.Sizeof(SizeOfA{0}) // 8
type SizeOfC struct {
A byte // 1字节
C int32 // 4字节
}
unsafe.Sizeof(SizeOfC{0, 0}) // 8
unsafe.Alignof(SizeOfC{0, 0}) // 4
//结构体中A byte占1字节,C int32占4字节. SizeOfC占8字节
内存对齐:
为何会有内存对齐?
1.并不是所有硬件平台都能访问任意地址上的任意数据。
2.性能原因 访问未对齐的内存,处理器需要做两次内存访问,而对齐的内存只需访问一次。 上面代码SizeOfC中元素一共5个字节,而实际结构体占8字节 是因为这个结构体的对齐倍数Alignof(SizeOfC) = 4.也就是说,结构体占的实际大小必须是4的倍数,也就是8字节。
type SizeOfD struct {
A byte
B [5]int32
}
unsafe.Sizeof(SizeOfD{}) // 24
unsafe.Alignof(SizeOfD{}) // 4
Alignof返回的对齐数是结构体中最大元素所占的内存数,不超过8,如果元素是数组那么取数组类型所占的内存值而不是整个数组的值

type SizeOfE struct {
A byte // 1
B int64 // 8
C byte // 1
}
unsafe.Sizeof(SizeOfE{}) // 24
unsafe.Alignof(SizeOfE{}) // 8
SizeOfE中,元素的大小分别为1,8,1,但是实际结构体占24字节,远超元素实际大小,因为内存对齐原因,最开始分配的8字节中包含了1字节的A,剩余的7字节不足以放下B,又为B分配了8字节,剩余的C独占再分配的8字节。

type SizeOfE struct {
A byte // 1
C byte // 1
B int64 // 8
}
unsafe.Sizeof(SizeOfE{}) // 16
unsafe.Alignof(SizeOfE{}) // 8
换一种写法,把A,C放到上面,B放到下面。这时SizeOfE占用的内存变为了16字节。因为首先分配的8字节足以放下A和C,省去了8字节的空间。 上面一个结构体中元素的不同顺序足以导致内存分配的巨大差异。前一种写法产生了很多的内存空洞,导致结构体不够紧凑,造成内存浪费。

下面我们来看一下结构体中元素的内存布局:
unsafe.Offsetof:返回结构体中元素所在内存的偏移量
type SizeOfF struct {
A byte
C int16
B int64
D int32
}
unsafe.Offsetof(SizeOfF{}.A) // 0
unsafe.Offsetof(SizeOfF{}.C) // 2
unsafe.Offsetof(SizeOfF{}.B) // 8
unsafe.Offsetof(SizeOfF{}.D) // 16
下图为内存分布图:

蓝色区域是元素实际所占内存,灰色为内存空洞。
下面总结一下go语言中各种类型所占内存大小(x64环境下):
X64下1机器字节=8字节
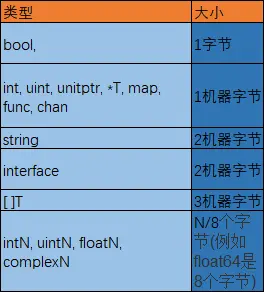
Golang内置类型占用内存大小
总结一下:
从例子中可以看出,结构体中元素不同顺序的排列会导致内存分配的极大差异,不好的顺序会产生许多的内存空洞,造成大量内存浪费。 虽然这几个函数都在unsafe包中,但是他们并不是不安全的。在需要优化内存空间时这几个函数非常有用。
面试官:谈谈 Go 内存对齐机制
大家好,我是木川
一、什么是内存对齐
Go 语言内存对齐机制是为了优化内存访问和提高性能而设计的。为了能让CPU可以更快的存取到各个字段,Go编译器会帮你把struct结构体做数据的对齐。所谓的数据对齐,是指内存地址是所存储数据大小(按字节为单位)的整数倍,以便CPU可以一次将该数据从内存中读取出来。编译器通过在结构体的各个字段之间填充一些空白已达到对齐的目的。
二、内存对齐系数
不同硬件平台占用的大小和对齐值都可能是不一样的,每个特定平台上的编译器都有自己的默认"对齐系数",32位系统对齐系数是4,64位系统对齐系数是8
不同类型的对齐系数也可能不一样,使用Go语言中的unsafe.Alignof函数可以返回相应类型的对齐系数,对齐系数都符合2^n这个规律,最大也不会超过8
package main
import (
"fmt"
"unsafe"
)
func main() {
fmt.Printf("bool alignof is %d\n", unsafe.Alignof(bool(true)))
fmt.Printf("string alignof is %d\n", unsafe.Alignof(string("a")))
fmt.Printf("int alignof is %d\n", unsafe.Alignof(int(0)))
fmt.Printf("float alignof is %d\n", unsafe.Alignof(float64(0)))
fmt.Printf("int32 alignof is %d\n", unsafe.Alignof(int32(0)))
fmt.Printf("float32 alignof is %d\n", unsafe.Alignof(float32(0)))
}
可以查看到各种类型在Mac 64位上的对齐系数如下:
bool alignof is 1
string alignof is 8
int alignof is 8
int32 alignof is 4
float32 alignof is 4
float alignof is 8
三、内存对齐的优点
- 提高可移植性,有些CPU可以访问任意地址上的任意数据,而有些CPU只能在特定地址访问数据,因此不同硬件平台具有差异性,这样的代码就不具有移植性,如果在编译时,将分配的内存进行对齐,这就具有平台可以移植性了
- 提高内存的访问效率,32位CPU下一次可以从内存中读取32位(4个字节)的数据,64位CPU下一次可以从内存中读取64位(8个字节)的数据,这个长度也称为CPU的字长。CPU一次可以读取1个字长的数据到内存中,如果所需要读取的数据正好跨了1个字长,那就得花两个CPU周期的时间去读取了。因此在内存中存放数据时进行对齐,可以提高内存访问效率。
四、内存对齐的缺点
- 存在内存空间的浪费,实际上是空间换时间
五、内存对齐原则
- 结构体变量中成员的偏移量必须是成员大小的整数倍
- 整个结构体的地址必须是最大字节的整数倍(结构体的内存占用是1/4/8/16byte…)
package main
import (
"fmt"
"runtime"
"unsafe"
)
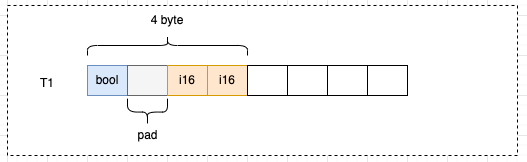
type T1 struct {
bool bool // 1 byte
i16 int16 // 2 byte
}
type T2 struct {
i8 int8 // 1 byte
i64 int64 // 8 byte
i32 int32 // 4 byte
}
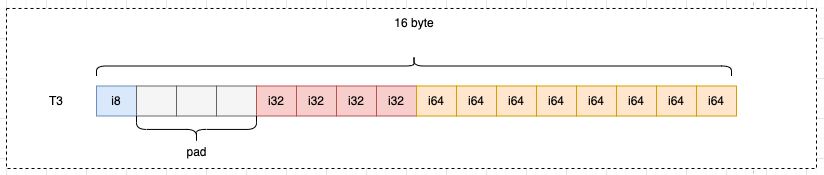
type T3 struct {
i8 int8 // 1 byte
i32 int32 // 4 byte
i64 int64 // 8 byte
}
func main() {
fmt.Println(runtime.GOARCH) // amd64
t1 := T1{}
fmt.Println(unsafe.Sizeof(t1)) // 4 bytes
t2 := T2{}
fmt.Println(unsafe.Sizeof(t2)) // 24 bytes
t3 := T3{}
fmt.Println(unsafe.Sizeof(t3)) // 16 bytes
}
以T1结构体为例,实际存储数据的只有3字节,但实际用了4字节,浪费了1个字节:
i16并没有直接放在bool的后面,而是在bool中填充了一个空白后,放到了偏移量为2的位置上。如果i16从偏移量为1的位置开始占用2个字节,就不满足对齐原则1,所以i16从偏移量为2的位置开始
以T2结构体为例,实际存储数据的只有13字节,但实际用了24字节,浪费了11个字节:

以T3结构体为例,实际存储数据的只有13字节,但实际用了16字节,浪费了3个字节:
「真诚赞赏,手留余香」
 kzdgt Blog
kzdgt Blog
真诚赞赏,手留余香
使用微信扫描二维码完成支付
