Golang的map是用哈希表实现的,在实现性能上非常优秀,这里会主要对map创建、插入、查询、删除以及删除全部的源码做详解,刻意避开了扩容以及迭代相关的代码,后续会用一个新的文章去讲述。Golang好几个版本都对map源码进行了重构,整体逻辑变化不大,但实现细节上有很大优化,下面介绍是1.12.5版本的源码。
1、名词解释
对哈希桶、桶链、桶、溢出桶做一下区分,方便后面阅读。

哈希桶
指整个哈希数组,数组内每个元素是一个桶。
桶链
哈希桶的一个桶以及该桶下挂着的所有溢出桶。
桶(bucket)
一个bmap结构,与溢出桶的区别在于它是哈希桶数组上的一个元素。
溢出桶(overflow bucket)
一个bmap结构,与桶区别是,它不是哈希桶数组的元素,而是挂在哈希桶数组上或挂在其它溢出桶上。
负载因子(overFactor)
表示平均每个哈希桶的元素个数(注意是哈希桶,不包括溢出桶)。如当前map中总共有20个元素,哈希桶长度为4,则负载因子为5。负载因子主要是来判断当前map是否需要扩容。
新、旧哈希桶
新、旧哈希桶的概念只存在于map扩容阶段,在哈希桶扩容时,会申请一个新的哈希桶,原来的哈希桶变成了旧哈希桶,然后会分步将旧哈希桶的元素迁移到新桶上,当旧哈希桶所有元素都迁移完成时,旧哈希桶会被释放掉。
2、整体设计
2.1 文件组成
map的源代码都在src/runtime目录下,主要由4个文件组成:
- map.go
- map_fast32.go
- map_fast64.go
- map_faststr.go
主体实现都在map.go文件中,其它三个文件分别对特点类型的key做了优化。如下:
- map_fast32.go,针对key类型为int32\uint32做了优化
- map_fast64.go,针对key类型为int\int64\uint64\pointer做了优化
- map_faststr.go,针对key类型为string做了优化
2.2 优化功能
- 插入
- 删除 (不包括删除全部)
- 查询 (不包括迭代遍历)
- 扩容迁移
2.3 优化具体内容
1 查询上的优化 (插入、删除、查询都会用到查询)
- 当只有一个哈希桶时,不计算hash值,直接遍历查找整个桶。
- 当多于一个哈希桶时
- fast32\64,省略了tophash的比较,在比较时直接比较key的值;
- string,省略了tophash的比较,多了一个字符串长度的比较,且在比较具体key时,直接通过内置的memequal。
2 内存管理上的优化 主要是在KV取值、数据拷贝、内存申请释放的优化,这块会在了解了内存管理方面知识后再来补充。
3. 数据结构
3.1 hmap
map实现的底层结构是hmap,每声明一个map就有一个hmap结构体与之对应,具体如下:
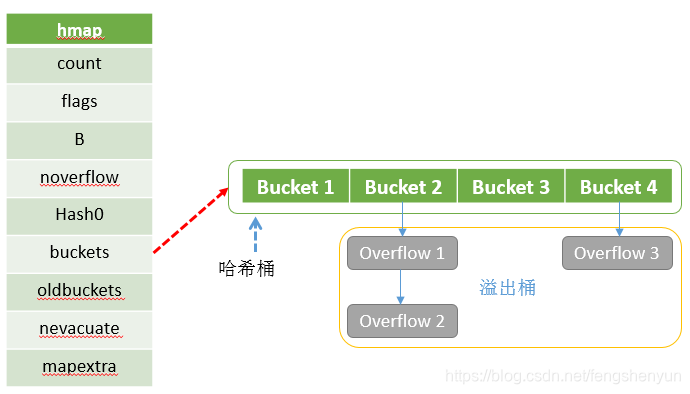
type hmap struct {
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}
- count:记录map当前元素个数
- flags:读、写、扩容、迭代等标记,用于记录map当前状态
- B:用于计算桶大小, bucketSize = 1 « B
- noverflow:溢出桶个数,当溢出桶个数过多时,这个值是一个近似值
- hash0:计算key哈希值的随机值,保证一个key在不同map中存放的位置是随机的
- buckets:当前哈希桶首地址
- oldbuckets:旧哈希桶首地址
- nevacuate:已迁移哈希桶个数
- extra:扩展字段,不一定每个map都需要,后续会详解
扩展一下,当map做为传参时,实际传入的是一个hmap指针。了解这一点,就能理解为什么在被调用方法里面对map做修改时,会在调用者里map也会改变。
package main
import "fmt"
func fn(m map[string]string) {
m["1"] = "2"
}
func main() {
m := make(map[string]string, 6)
m["1"] = "1"
fn(m)
fmt.Printf("%#v\n", m)
}
结果为:
map[string]string{"1":"2"}
3.2 bmap
bmap(bucket map),描述一个桶,即可以是哈希桶也可以是溢出桶。但下面的结构体只含有一个tophash,用于桶内快速查找,并没有存K/V的地方。从下面定义里面两个Followed定义可以看出,其实bmap只给出了部分字段的描述,后面还有一块存K/V的内存,以及一个指向溢出桶的指针。之所以不给出全部描述,是因为K/V的内存块大小会随着K/V的类型不断变化,无法固定写死,在使用时也只能通过指针偏移的方式去取用。
type bmap struct {
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt values.
// Followed by an overflow pointer.
}
真实描述(伪代码):
type bmap struct {
tophash [bucketCnt]uint8
keys [bucketCnt]KeyType
values [bucketCnt]ValueType
overflow *bmap
}
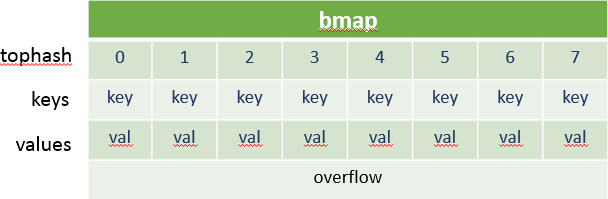
- tophash:一个长度为8的数据,会存放key的hash值的高8位,用于后续快速查找桶内元素。
- keys/values:key/value存储的地方。
- overflow,指向下一个桶(溢出桶)。
4 源码解析
4.1. map创建
4.1.1 语法
- 不带参数
make(map[keyType]valueType)
- 带参数
make(map[keyType]valueType, size)
4.1.2 源码分析
整体思路
- 创建hmap,并初始化。
- 获取一个随机种子,保证同一个key在不同map的hash值不一样(安全考量)。
- 计算初始桶大小。
- 如果初始桶大小不为0, 则创建桶,有必要还要创建溢出桶结构。
源码
func makemap(t *maptype, hint int, h *hmap) *hmap {
...
// 1. initialize Hmap
if h == nil {
h = new(hmap)
}
// 2. initialize hash rand
h.hash0 = fastrand()
// 3. calcate bucket size
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
// 4. allocate initial hash table
// if B == 0, the buckets field is allocated lazily later (in mapassign)
// If hint is large zeroing this memory could take a while.
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}
4.1.3 哈希桶初始大小
在创建map时,当没有指定size大小或size为0时,不会创建哈希桶,会在插入元素时创建,避免只申请不使用导致的效率和内存浪费。当size不为0时,会根据size大小计算出哈希桶的大小,具体计算算法如下:
源码
func overLoadFactor(count int, B uint8) bool {
return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}
写了个小demo来探测size对bucket长度的影响,大致是这样:
- (1) size <9,bucketLen = 1 (2^0) B=0
- (2) size < 14,bucketLen = 2 (2^1) B=1
- (3) size < 27,bucketLen = 4 (2^2) B=2
- (4) size < 53,bucketLen = 8 (2^3) B=3
- (5) size < 104,bucketLen = 16 (2^4) B=4
- …
从这些数据反推overLoadFactor方法的函义:
- 第二行与第一行size之差A=5,bucket长度差为1,A/B=5。
- 第三行与第二行size之差A=13,bucket长度差B=2,A/B=6.5。
- 第四行与第三行size之差A=26,bucket长度差B=4,A/B=6.5。
- 第五行与第四行size之差A=51,bucket长度差B=8,A/B=6.375。
- …
结论: 1 哈希桶的大小是2的整数次幂 2 哈希桶大小 = size / 6.5
验证demo
package main
import "fmt"
func bucketShift(b uint8) uintptr {
return uintptr(1) << b
}
func overLoadFactor(count int, B uint8) bool {
return count > 8 && uintptr(count) > 13*(bucketShift(B)/2)
}
func bucketLen(hint int) uint8 {
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
return B
}
func main() {
for i := 0; i < 100; i++ {
fmt.Println(i, bucketLen(i))
}
}
4.2 map查找
4.2.1 语法
- 第一种用法,只返回value值,当key在map中没有找到时,返回value对应类型的默认值。
m := make(map[string]int)
print(m["1"]) -- 结果为: 0 (返回int对应的默认值)
- 第二种用法,返回value值以及key是否存在标志
m := make(map[string]int)
val, ok := m["1"]
print(val, ok) -- 结果为:0, false
- 第三种用法,返回key和value,只用于range迭代场景
m := make(map[string]int)
for k, v := range m {
}
4.2.2 源码分析
三种方法的对处理查找逻辑的源码差不多,差别只是在于返回值,只需分析一个方法的源码即可。
整体思路
- 校验map是否正在写,如果是,则直接报"concurrent map read and map write"错误
- 计算key哈希值,并根据哈希值计算出key所在桶链位置
- 计算tophash值,便于快速查找
- 遍历桶链上的每一个桶,并依次遍历桶内的元素
- 先比较tophash,如果tophash不一致,再比较下一个,如果tophash一致,再比较key值是否相等
- 如果key值相等,计算出value的地址,并取出value值,并直接返回
- 如果key值不相等,则继续比较下一个元素,如果所有元素都不匹配,则直接返回value类型的默认值
源码
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
// 判断是否正在写,如果是直接报错
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
// 计算key哈希值
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
// 计算桶链首地址
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// 计算tophash值
top := tophash(hash)
bucketloop:
// 遍历桶链每个桶
for ; b != nil; b = b.overflow(t) {
// 遍历桶的元素
for i := uintptr(0); i < bucketCnt; i++ {
// 如果tophash不相等,continue
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// tophash相等
// 获取当前位置对应的key值
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
// 如果与key匹配,表明找到了,直接返回value值
if alg.equal(key, k) {
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
if t.indirectvalue() {
v = *((*unsafe.Pointer)(v))
}
return v
}
}
}
// 一直没有找到,返回value类型的默认值
return unsafe.Pointer(&zeroVal[0])
}
4.3 map插入(更新)
map的添加和更新是通过一个方法实现的,在往map里面插入一个K/V时,如果key已经存在,就直接覆盖更新;如果key不存在,就插入map。
4.3.1 语法
m[key] = value
4.3.2 源码分析
整体思路
1 校验map是否正在写,如果是,则直接报"concurrent map writes"错误 2 设置写标志 3 计算key的哈希值 4 如果哈希桶是空的,则创建哈希桶,桶大小为1 5 计算桶链首地址和tophash 6 找到桶链下的所有桶的元素,看key是否已经存在,如果存在,直接把value写入对应位置,跳到步骤10 7 在查找过程中,会记录下桶里面第一个空元素的位置 8 如果没有空位置,则需要申请一个溢出桶,并把该溢出桶挂在该桶链下 9 把K/V插入到空闲位置 10 map元素总个数加1 11 清除写标志
源码
func mapassign(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
...
// 如果正在写,则直接报错
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
// 计算插入key的hash值
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
// 设置写标记
h.flags ^= hashWriting
// 如果当前哈希桶为空,则新建一个大小为1的哈希桶
if h.buckets == nil {
h.buckets = newobject(t.bucket) // newarray(t.bucket, 1)
}
again:
// 计算桶链的位置以及tophash
bucket := hash & bucketMask(h.B)
...
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + bucket*uintptr(t.bucketsize)))
top := tophash(hash)
// 用于记录第一个空闲k/V的位置
var inserti *uint8
var insertk unsafe.Pointer
var val unsafe.Pointer
bucketloop:
// 遍历桶链的每个桶
for {
// 遍历桶内元素
for i := uintptr(0); i < bucketCnt; i++ {
// tophash不相等,继续判断下一个元素
if b.tophash[i] != top {
// 记录第一个空闲K/V位置
if isEmpty(b.tophash[i]) && inserti == nil {
inserti = &b.tophash[i]
insertk = add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
}
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// tophash相等
// 获取当前位置对应的key值
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
// 如果不相等,继续比较下一个
if !alg.equal(key, k) {
continue
}
// 更新key
if t.needkeyupdate() {
typedmemmove(t.key, k, key)
}
// 更新value
val = add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
goto done
}
// 计算下一个桶的地址
ovf := b.overflow(t)
// 如果桶链下的元素全部遍历完了,则退出遍历
if ovf == nil {
break
}
b = ovf
}
// 没有匹配到key, 即刚插入的K/V是新增
// 如果没有找到空闲位置,则新申请一个新溢出桶,并把新溢出桶挂到桶链上
// 将inserti,insertk指向空闲K/V位置
if inserti == nil {
// all current buckets are full, allocate a new one.
newb := h.newoverflow(t, b)
inserti = &newb.tophash[0]
insertk = add(unsafe.Pointer(newb), dataOffset)
val = add(insertk, bucketCnt*uintptr(t.keysize))
}
// 插入key
if t.indirectkey() {
kmem := newobject(t.key)
*(*unsafe.Pointer)(insertk) = kmem
insertk = kmem
}
// 插入value
if t.indirectvalue() {
vmem := newobject(t.elem)
*(*unsafe.Pointer)(val) = vmem
}
typedmemmove(t.key, insertk, key)
*inserti = top
// map元素加1
h.count++
done:
// 现次判断是否有并发写
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
// 清空写标记
h.flags &^= hashWriting
if t.indirectvalue() {
val = *((*unsafe.Pointer)(val))
}
return val
}
4.4 map删除
4.4.1 语法
delete(map, key)
4.4.2 源码分析
整体思路
1 校验map是否正在写,如果是,则直接报"concurrent map writes"错误 2 设置写标志 3 计算key的哈希值 4 计算桶链首地址和tophash 5 找到桶链下的所有桶的元素,如果找到key,处理指针相关(这块后面详解) 6 设置该位置的tophash值,这个逻辑比较复杂,详细会在tophash详解里面介绍 7 map总元素个数减1 8 清除写标志
源码
func mapdelete(t *maptype, h *hmap, key unsafe.Pointer) {
...
// 如果正在写,则直接报错
if h.flags&hashWriting != 0 {
throw("concurrent map writes")
}
// 计算插入key的hash值
alg := t.key.alg
hash := alg.hash(key, uintptr(h.hash0))
// 设置写标记
h.flags ^= hashWriting
// 计算桶链的位置以及tophash
bucket := hash & bucketMask(h.B)
...
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
bOrig := b
top := tophash(hash)
search:
// 遍历桶链每个桶
for ; b != nil; b = b.overflow(t) {
// 遍历桶的每个元素
for i := uintptr(0); i < bucketCnt; i++ {
// tophash不相等,继续判断下一个元素
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break search
}
continue
}
// tophash相等
// 获取当前位置对应的key值
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
k2 := k
if t.indirectkey() {
k2 = *((*unsafe.Pointer)(k2))
}
// 如果不相等,继续比较下一个
if !alg.equal(key, k2) {
continue
}
// 如果是指针或含有指针,处理指针
if t.indirectkey() {
*(*unsafe.Pointer)(k) = nil
} else if t.key.kind&kindNoPointers == 0 {
memclrHasPointers(k, t.key.size)
}
// 计算出value位置,处理指针
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
if t.indirectvalue() {
*(*unsafe.Pointer)(v) = nil
} else if t.elem.kind&kindNoPointers == 0 {
memclrHasPointers(v, t.elem.size)
} else {
memclrNoHeapPointers(v, t.elem.size)
}
// 重新计算该位置tophash的值
b.tophash[i] = emptyOne
...
notLast:
// map总元素个数减1
h.count--
break search
}
}
// 清空写标记
if h.flags&hashWriting == 0 {
throw("concurrent map writes")
}
h.flags &^= hashWriting
}
4.5 map删除所有
4.5.1 用法
通过Go的内部函数mapclear方法删除。这个函数并没有显示的调用方法,当你使用for循环遍历删除所有元素时,Go的编译器会优化成Go内部函数mapclear。
for k := range m {
delete(m, k)
}
4.5.2 demo分析
package main
func main() {
m := make(map[byte]int)
m[1] = 1
m[2] = 2
for k := range m {
delete(m, k)
}
}
把上述源代码直接编译成汇编(默认是有编译器优化的):
go tool compile -S map_clear.go
可以看到编译器把源码9行的for循环直接优化成了mapclear去删除所有元素。
4.5.3 源码分析
这部分代码涉及到内存管理和GC,只能看懂个大概,后续再补充。
整体思路
- 清空统计数据,如元素个数、溢出数等。
- 重新申请一个新的extra,原有的extra交给GC。
- 释放桶内存块。
源码
func mapclear(t *maptype, h *hmap) {
...
// 把oldbuckets置nil,如果有oldbuckets就让GC处理
h.oldbuckets = nil
// 初始化溢出数、元素个数
h.nevacuate = 0
h.noverflow = 0
h.count = 0
// 重新申请一个新的extra,旧的交给GC回收
if h.extra != nil {
*h.extra = mapextra{}
}
// 清空bucket
_, nextOverflow := makeBucketArray(t, h.B, h.buckets)
...
}
「真诚赞赏,手留余香」
 kzdgt Blog
kzdgt Blog
真诚赞赏,手留余香
使用微信扫描二维码完成支付
