


概述
锁是一种常见的同步机制,用来解决多个线程同时访问共享资源导致的数据竞争问题。在高并发场景下,锁的使用可能会成为性能瓶颈,因为线程需要频繁地加锁和释放锁,这会增加上下文切换开销并降低程序的吞吐量。
无锁编程(lock-free programming)是一种并发编程技术,主要用于消除多线程编程中锁操作带来的性能损耗。
如果对一个共享的数据结构的所有操作都不需要加锁 (这里的操作一般指读写操作),那么该结构就是 无锁(lock free)的,将数据结构和操作的组合简称为 无锁编程。
优势
- 减少线程阻塞和等待时间
- 避免线程的优先级反转
- 提高并发性能
- 消除竞态条件(race condition)、死锁、饿死等潜在问题
- 代码更加清晰易懂
常用技术
现在几乎所有的 CPU 指令都支持 CAS 的原子操作,我们可以直接用 CAS 来实现 无锁(lock free)的数据结构。
CAS
通过对内存中的值与指定新值进行比较,仅当两个数值一致时,将内存中的数据替换为新的值。
CAS (compare and swap) 是原子操作的一种,用于在多线程中实现原子数据交换,避免多线程同时改写某一共享数据时,由于执行顺序不确定性以及中断的不可预知性产生的数据不一致问题。
使用方法
在使用上,通常会记录下某块内存中的旧值,通过对旧值进行一系列的操作后得到新值,然后通过 CAS 操作将新值与旧值进行交换。
如果这块内存的值在这期间内没被修改过,则旧值会与内存中的数据相同,这时 CAS 操作将会成功执行,使内存中的数据变为新值。 如果内存中的值在这期间内被修改过,则旧值会与内存中的数据不同,这时 CAS 操作将会失败,新值将不会被写入内存。
Go 的标准库中的 atomic 包提供了 atomic.CompareAndSwap* 系列方法来提供 CAS 操作 API。
func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool)
func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool)
...
func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool)
有锁编程 和 无锁编程 的性能差距有多少呢?我们通过基准测试来比较一下。
示例: 栈操作
我们通过一个简单的程序来做演示,程序实现了数据结构 栈 的两个操作 Push, Pop。
// Stack 接口
type StackInterface interface {
Push(interface{})
Pop() interface{}
}
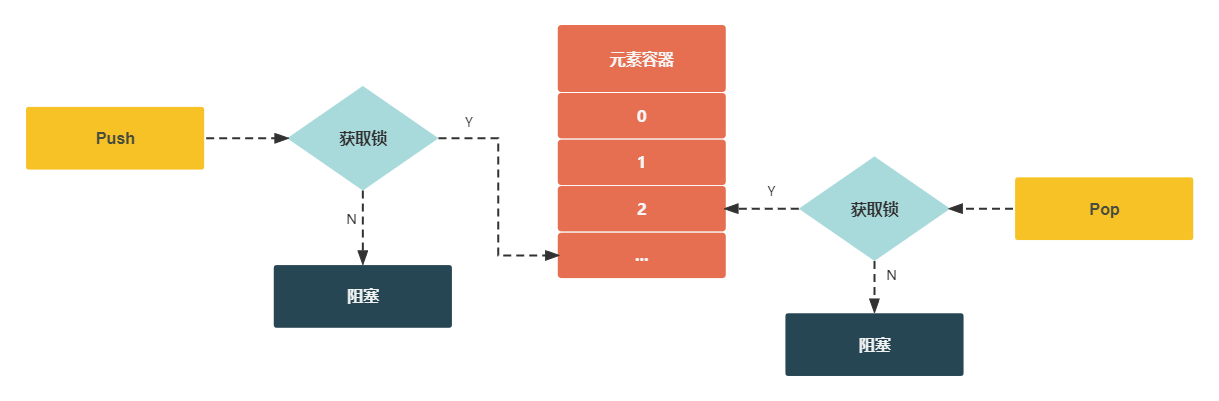
有锁编程
// 互斥锁实现的栈 (有锁编程)
type MutexStack struct {
// 栈元素容器用切片表示
v []interface{}
// 互斥锁
mu sync.Mutex
}
func NewMutexStack() *MutexStack {
return &MutexStack{v: make([]interface{}, 0)}
}
func (s *MutexStack) Push(v interface{}) {
// 可能同时有多个 goroutine 操作
// 栈元素操作为临界区,需要加锁
s.mu.Lock()
s.v = append(s.v, v)
s.mu.Unlock()
}
func (s *MutexStack) Pop() interface{} {
// 可能同时有多个 goroutine 操作
// 栈元素操作为临界区,需要加锁
s.mu.Lock()
var v interface{}
if len(s.v) > 0 {
v = s.v[len(s.v)-1]
s.v = s.v[:len(s.v)-1]
}
s.mu.Unlock()
return v
}
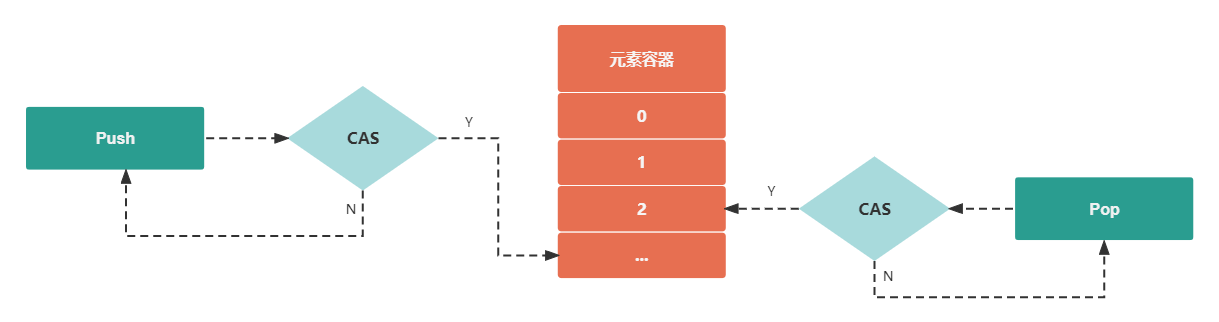
无锁编程
// 栈元素节点
type directItem struct {
next unsafe.Pointer
v interface{}
}
// CAS 操作实现的栈 (无锁编程)
type LockFreeStack struct {
// 栈元素容器用链表表示
top unsafe.Pointer
// 栈长度
len uint64
}
func NewLockFreeStack() *LockFreeStack {
return &LockFreeStack{}
}
func (s *LockFreeStack) Push(v interface{}) {
item := directItem{v: v}
var top unsafe.Pointer
for {
top = atomic.LoadPointer(&s.top)
item.next = top
if atomic.CompareAndSwapPointer(&s.top, top, unsafe.Pointer(&item)) {
// 只有 1 个 goroutine 可以执行到这里
// 栈元素数量 + 1
atomic.AddUint64(&s.len, 1)
return
}
}
}
func (s *LockFreeStack) Pop() interface{} {
var top, next unsafe.Pointer
var item *directItem
for {
top = atomic.LoadPointer(&s.top)
if top == nil {
return nil
}
item = (*directItem)(top)
next = atomic.LoadPointer(&item.next)
if atomic.CompareAndSwapPointer(&s.top, top, next) {
// 只有 1 个 goroutine 可以执行到这里
// 栈元素数量 - 1
atomic.AddUint64(&s.len, ^uint64(0))
return item.v
}
}
}
测试代码
func Benchmark_Stack(b *testing.B) {
rand.Seed(time.Now().UnixNano())
// 初始化测试的随机参数
length := 1 << 12
inputs := make([]int, length)
for i := 0; i < length; i++ {
inputs[i] = rand.Int()
}
ls, ms := NewLockFreeStack(), NewMutexStack()
b.ResetTimer()
for _, s := range [...]StackInterface{ls, ms} {
b.Run(fmt.Sprintf("%T", s), func(b *testing.B) {
var c int64
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
i := int(atomic.AddInt64(&c, 1)-1) % length
v := inputs[i]
if v >= 0 {
s.Push(v)
} else {
s.Pop()
}
}
})
})
}
}
测试结果比较
运行测试代码:
$ go test -run='^$' -bench=. -count=1 -benchtime=2s
## 输出结果如下
Benchmark_Stack/*performance.LockFreeStack-8 16553013 134.0 ns/op
Benchmark_Stack/*performance.MutexStack-8 20625786 172.5 ns/op
通过输出结果可以看到,使用 CAS 实现的无锁方案的性能要优于使用 Mutex 实现的有锁方案。这里仅仅是一个简陋的测试实现,感兴趣的读者可以在此基础上改进, 例如提高 goroutine 的数量,栈 的入栈、出栈比例等,然后观察无所方案带来的性能优势。
标准库中的无锁编程
- sync.WaitGroup 中的
state字段 - sync.Pool 中的
poolDequeue.headTail字段
详情可以阅读之前的文章。
小结
atomic 包提供的 CAS 操作是一个相对底层的调用,在标准库中的很多实现中,都可以看到其身影。
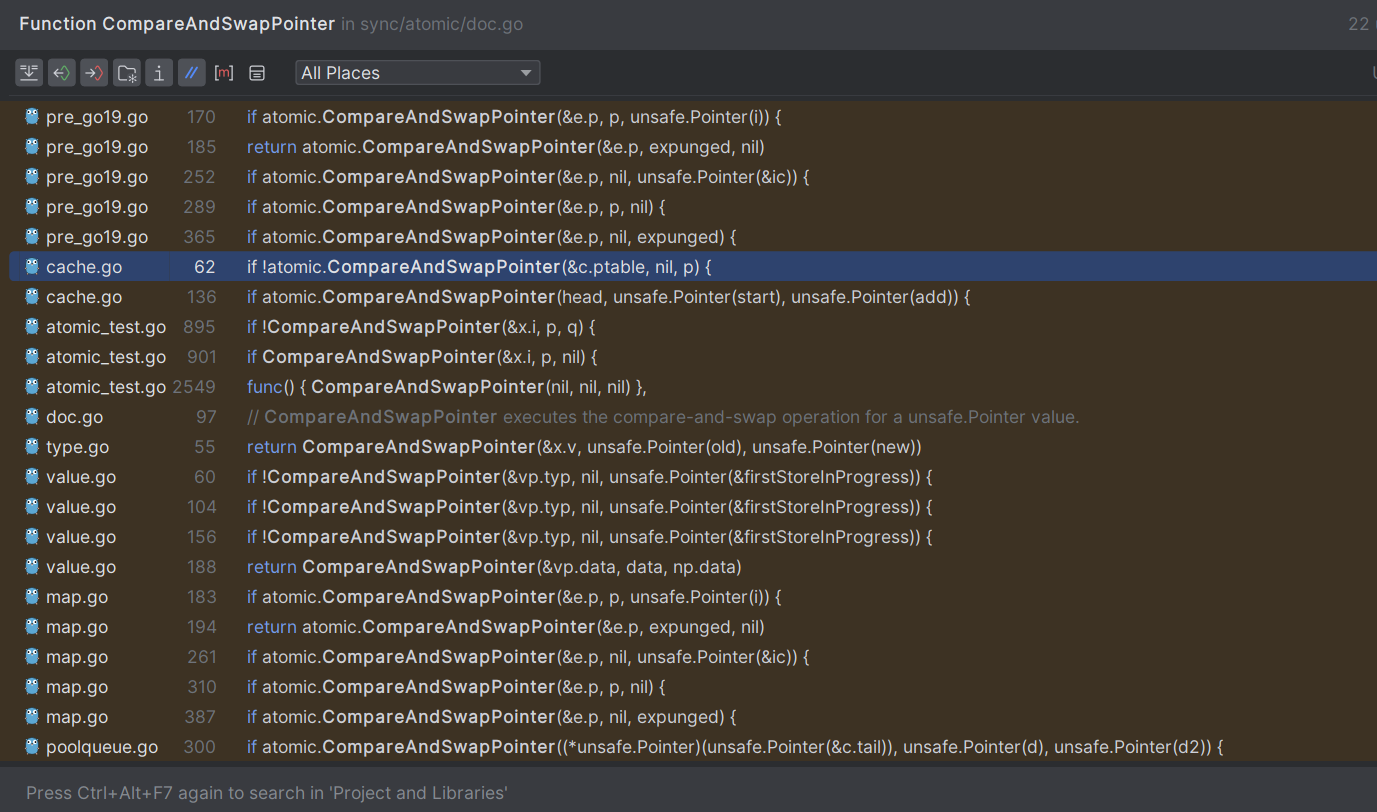
篇幅所限,这里给出标准库中 atomic.CompareAndSwapPointer 方法调用方的部分截图。
针对性能敏感场景或者 hot path 中的锁操作,可以使用 CAS 来进行对应的优化,此外,我们可以通过阅读标准库中的源代码,来学习和理解 CAS 以及原子操作的最佳实践。
如果从业务开发场景来感受的话,CAS 直觉上很像 乐观锁,而 互斥锁 很像 悲观锁。
参与讨论
(Participate in the discussion)
参与讨论